

Artificial intelligence helps people generate new text such as essays and poems with the help of tools like ChatGPT. Stable Diffusion is the best example of the capabilities of AI to generate images by using text and image prompts. You can also use Stable Diffusion to create videos as well as animations for diverse purposes. Stable Diffusion is a popular generative AI model that has attracted the attention of the whole world towards diffusion technology.
The special highlights of Stable Diffusion such as latent space ensure that you can run the model with limited processing requirements. You can make the most of Stable Diffusion on desktops or laptops with GPUs. It is also important to note that you can fine-tune Stable Diffusion to fulfill specific requirements with the help of transfer learning. Let us learn more about the working mechanism of Stable Diffusion with a detailed understanding of its architecture.
Grab the opportunity to become a certified AI professional and make a successful career with our AI Certification Course.
Understanding the Importance of Stable Diffusion
The first question on your minds right now must be about the reasons to learn the working mechanism of Stable Diffusion. You must learn about Stable Diffusion AI working principles to capitalize on its various advantages. The foremost highlights of Stable Diffusion include easier usability and accessibility. Users can run Stable Diffusion on machines with consumer-grade GPUs, thereby addressing the issues of accessibility.
The lower barriers to accessibility ensure that anyone can download Stable Diffusion and use it to generate images. It also offers better control over the important hyperparameters including the degree of noise and number of denoising steps. Stable Diffusion does not impose the burden of technical complexities on users who want to generate images.
The active community of Stable Diffusion also offers support to users in the form of helpful tutorials and comprehensive documentation. Stable Diffusion works with the Creative ML OpenRAIL-M license that helps in using, changing and redistributing modified software. Developers can create derivative software and release it with the same license alongside a copy of the original license of Stable Diffusion.
Learn how AI can boost your business and take it to new heights with our unique AI for Business Course. Enroll now!
Discovering the Important Components of Stable Diffusion
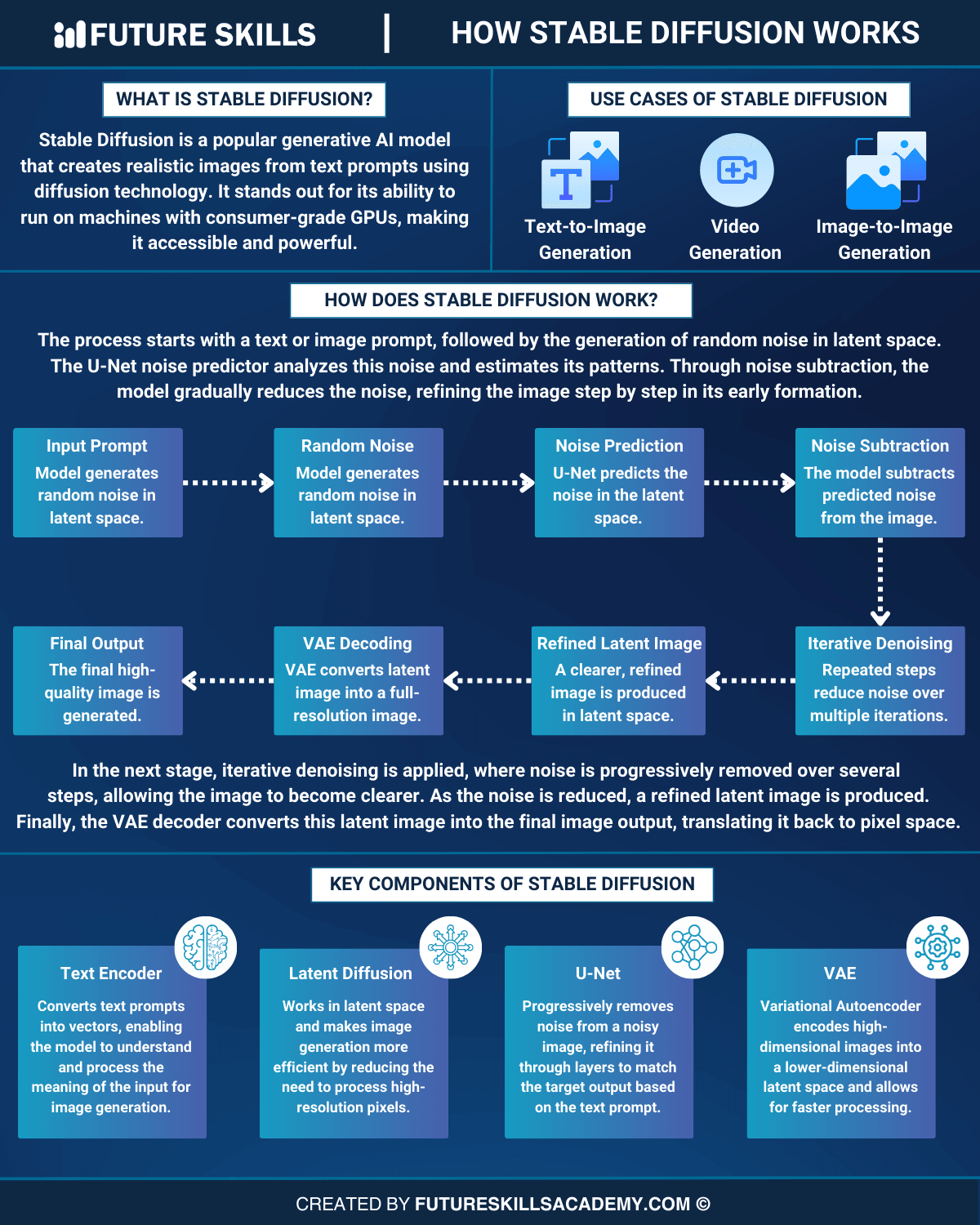
The best way to understand the working mechanism of Stable Diffusion involves learning about its architecture. You can find out how Stable Diffusion works by figuring out the functionalities of each component in its architecture. The important components of Stable Diffusion architecture include noise predictor, variational autoencoder, text conditioning and forward and reverse diffusion. Let us discover how each component supports Stable Diffusion in generating realistic images.
-
Variational Autoencoder
Variational autoencoder includes a distinct decoder and encoder which define its functionality for enhancing the way Stable Diffusion works. The encoder helps in compression of the 512×512 pixel images to a 64×64 model in latent space. The latent space offers better scope for manipulation. On the other hand, the decoder works on restoring the small model from latent space to full-size images.
-
Forward Diffusion
The forward diffusion component in the architecture of Stable Diffusion is an integral requirement for generating images from prompts. Forward diffusion involves progressive addition of Gaussian noise to an image. It helps in creating an image that is filled with random noise to an extent that you cannot find the original image. Forward diffusion is essential during the training process and you don’t need it in any other situation except for image-to-image conversions.
-
Reverse Diffusion
Reverse Diffusion is another crucial addition to the Stable Diffusion workflow for reversing the forward diffusion process. It is a parameterized process which reverses the forward diffusion process in an iterative manner. Let us assume that you have trained the model with only two images in the forward diffusion process. The reverse diffusion process would drift towards either of the two images without hanging in between.
-
Text Conditioning
Stable Diffusion generates images from text prompts, thereby implying the necessity of text conditioning to optimize prompts for the model. The CLIP tokenizer helps with text conditioning in the Stable Diffusion architecture. The tokenizer supports the working of Stable Diffusion by analyzing text prompts and embedding the data in a 786-value vector.
Stable Diffusion supports the use of only 75 tokens in one prompt. The model feeds prompts to the U-net noise predictor from the text encoder with a text transformer. Stable Diffusion users can create different types of images in the latent space by specifying a random number generator as the seed.

Unraveling the Steps in the Working Mechanism of Stable Diffusion
Stable Diffusion stands out as one of the most powerful image generation models with its unique capabilities. Diffusion models depend on Gaussian noise for encoding an image. Subsequently, they use a combination of reverse diffusion process and a noise predictor to generate the image from the noise. Stable Diffusion is different as it does not depend on the pixel space of the concerned image.
The Stable Diffusion AI working mechanism leverages a latent space with reduced definition. It reduces the processing requirements by a significant margin. The variational autoencoder in Stable Diffusion helps in creating fine details such as eyes with better clarity. You can understand the working mechanism of Stable Diffusion more easily with the following steps.
-
Text-to-Image Conversion
The working mechanism of Stable Diffusion involves generating random tensors in the latent space of the model. The random number generator seed helps in determining the tensor which serves as a representation of the image in latent form with noise.
-
Noise Prediction
The U-net noise predictor comes into play in the second step of the Stable Diffusion working mechanism. Stable Diffusion uses the latent noise image and the text prompt as inputs for the noise predictor. It helps in predicting the noise in the latent space.
-
Noise Removal
The noise removal process involves subtracting the latent noise from the initial image. It would lead to the generation of a new image. The Stable Diffusion workflow involves repeating the noise prediction and removal processes for a specific amount of sampling steps. The recommended number of iterations to achieve the desired result is almost 20.
-
Decoding
Decoding is the final step that uses the variational autoencoder or VAE decoder. It helps in conversion of the latent image to the pixel space to generate the final image.
Learn how to write precise prompts for ChatGPT and become a professional with our accredited ChatGPT Certification Course.
Identifying the Use Cases of Stable Diffusion
Stable Diffusion has achieved significant advancements in the domain of text-to-image generation. The availability of Stable Diffusion and limited processing power requirements make it a better alternative to other image generation models. It offers distinctive capabilities that can help you achieve the best results in the following applications.
-
Text-to-Image Generation
The most common application of Stable Diffusion is the generation of images from text prompts. You can use Stable Diffusion to generate different images by adapting the seed number to fit with the random generator. Another approach involves modifying the denoising schedule to achieve unique effects.
-
Image-to-Image Generation
Stable Diffusion also supports the generation of images from images and text prompts. The most common example of such applications involves using a sketch and relevant prompts to create new images.
-
Video Generation
You can also rely on Stable Diffusion to generate new videos with the help of prompts. The flexibility to access features like Deforum with Stable Diffusion help you generate short video clips and animation videos. It also helps in adding different styles to the videos with your creativity. Stable Diffusion also helps you with animation of photos by generating an impression of fluid motion.
-
Artwork, Graphics and Logo Generation
In-depth understanding of how Stable Diffusion works offers a clear impression of its diverse capabilities. You can use a diverse array of prompts to generate logos, artwork and graphics in different styles with Stable Diffusion. It is difficult to determine the output in such applications. Users can rely on sketches to guide the process of logo creation by using Stable Diffusion.
-
Image Retouching and Editing
Another promising application of Stable Diffusion points at the flexibility for retouching and editing images. Users can make the most of an AI Editor to load images and use eraser brush to cover the area you choose for the edit. In the next step, you can use a prompt that defines how you want to edit or retouch the image. You can rely on such capabilities of Stable Diffusion to remove objects from photos or add new features, change the features or repair old images.
Final Thoughts
Generative AI has evolved as a formidable example of how artificial intelligence can become a part of our everyday lives. Users can choose advanced generative AI models such as Stable Diffusion to create realistic images and artwork with text prompts. You can notice that the working of Stable Diffusion depends on the important components in its architecture. The components of Stable Diffusion such as variational autoencoder, forward and reverse diffusion and the noise predictor empower the generative AI model.
Stable Diffusion is different from the other generative AI models for image generation. It is easier to use and offers better accessibility with limited processing requirements. Learn more about Stable Diffusion and how to use it in the real world across a diverse range of applications now.

About Author
James Mitchell is a seasoned technology writer and industry expert with a passion for exploring the latest advancements in artificial intelligence, machine learning, and emerging technologies. With a knack for simplifying complex concepts, James brings a wealth of knowledge and insight to his articles, helping readers stay informed and inspired in the ever-evolving world of tech.



