

The three popular tools, such as ChatGPT, Google, and Wolfram Alpha, could interact with users through a single line of text. However, the fundamentals of how ChatGPT works would be significantly different in comparison to other tools. Google can provide search results in the form of a list of web pages or articles that can solve your queries. On the other hand, Wolfram Alpha helps in generating answers for queries involving mathematics and data analytics.
How does ChatGPT respond to your queries in the form of a single line of text? It will provide a response to the user query according to the intent and context underlying the questions for users. ChatGPT is capable of tasks that you cannot get done by Google or Wolfram Alpha. For example, ChatGPT can help you create the code of an API module or write a creative story.
Google works by exploring the massive database stores to obtain the relevant matches according to user queries. Wolfram Alpha can break down data-related questions and conduct the necessary calculations for the question. At the same time, a description of how ChatGPT works sheds light on its ability to parse queries and produce human-like responses. It can provide responses according to knowledge learned from a massive repository of text-based information. The following post helps you dive deeper into ChatGPT working and its architecture.
Become a certified ChatGPT expert and learn how to utilize the potential of ChatGPT that will open new career paths for you. Enroll in Certified ChatGPT Professional (CCGP)™ Certification.
What is ChatGPT?
The review of the working process of ChatGPT requires comprehensive knowledge of the underlying models. GPT model or Generative Pre-trained Transformer model involves the use of GPT-3 and introduced GPT-4 for ChatGPT Plus subscribers. GPT models have been created by OpenAI, and they could power other use cases, such as AI features of Bing and writing tools such as Copy.ai and Jasper.
The answers to “How exactly does ChatGPT work?” would also emphasize the identity of GPT-3 and GPT-4 as Large Language Models or LLMs. It is also important to notice the arrival of competitors such as the AI chatbot of Google, Bard, which utilizes a custom language model.
ChatGPT is still the benchmark for Artificial intelligence language models, and you can understand how it works by referring to the high-level overview of the tool. It is an app by OpenAI and uses GPT language models for answering questions, drafting emails, and writing copies of text. The outline of ChatGPT working process would also refer to use cases of the AI chatbot for an explanation of code in different programming languages. It can also help you explain code in various programming languages and support the translation of natural language to programming logic.
As of now, ChatGPT provides two distinct GPT models such as GPT-3.5 and GPT-4. GPT-3.5 is the default model in ChatGPT, while the GPT-4 model is available for ChatGPT Plus Subscribers only. You must also notice that ChatGPT remembers the conversations you have with the AI chatbot to understand the context. Therefore, interactions with ChatGPT would feel like you are communicating with another individual.
Level up your ChatGPT skills and kickstart your journey towards superhuman capabilities with Free ChatGPT and AI Fundamental Course.
Important Stages in the Working of ChatGPT
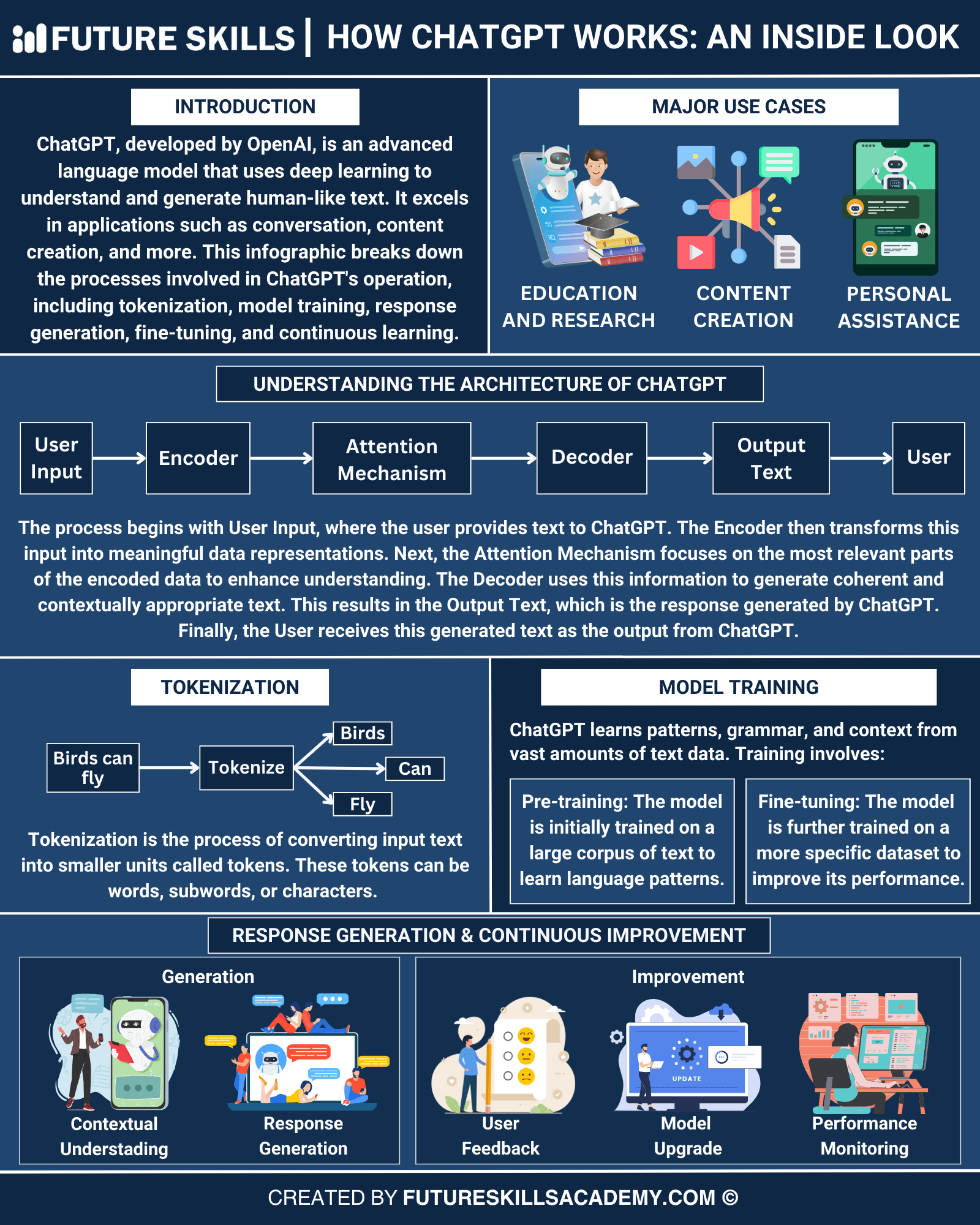
You might still have some doubts about the ChatGPT working principle after hearing about the GPT models. How do the ChatGPT models work? How can a beginner understand the fundamental principles behind the working of ChatGPT? Beginners can use the analogy to Google as an effective way to understand the working of ChatGPT.
Does Google search all over the web to find the answers to your queries? No, Google searches through the database to find pages that match your request. Therefore, you can notice two distinct stages in the working of Google. First of all, you have the spidering and data-gathering stage, followed by the user interaction or lookup phase.
You can also apply the same principle to understand the working process of ChatGPT. The outline of ChatGPT working explained for beginners suggests that the data gathering phase is the pre-training for GPT models. The user interaction or lookup stage in ChatGPT is known as inference. One of the most prominent reasons for the sudden explosion in popularity of ChatGPT and generative AI is the scalability of pre-training tasks. How? The continuous growth of innovation in cloud computing and hardware technology has fostered promising improvements in scalability of pre-training.
Embark on a transformative journey into AI, unlocking career-boosting superpowers through our Certified AI Professional (CAIP)™ Certification program.
Pre-Training the AI behind ChatGPT
Pre-training is a crucial stage in the learning of an AI model like ChatGPT. You can find more information on how ChatGPT works by identifying the mandatory approaches, such as supervised and non-supervised learning. Prior to ChatGPT and the emerging array of generative AI systems, supervised learning approach served as the primary choice for AI projects. Supervised pre-training involves training an AI model with a labeled dataset in which every input has a corresponding output.
The common examples of supervised pre-training point at training of AI on the dataset for customer service interactions. In such cases, the questions and complaints of users must be labeled with suitable responses from customer support executives. The explanation for ChatGPT working methodology shows that supervised learning enables feeding the model with questions and relevant answers. Therefore, the model works through a mapping function for accurate mapping of inputs to outputs. Supervised pre-training has proved effective in tasks such as sequence labeling, classification, and regression.
However, supervised learning also draws attention to limitations of ChatGPT. For example, it can showcase setbacks in the lack of knowledge regarding different subjects. It is practically impossible to assume and feed all the questions a user could ask to ChatGPT. Therefore, it is difficult to establish any relationship between supervised learning and ChatGPT. On the contrary, ChatGPT relies on a non-supervised pre-training approach for delivering its broad range of functionalities.
Excited to understand the crucial requirements for developing responsible AI and the implications of privacy and security in AI, Enroll now in the Ethics of Artificial Intelligence (AI) Course
How Does Non-Supervised Learning Help ChatGPT?
ChatGPT relies on non-supervised pre-training as it focuses on training with data without any association between inputs and outputs. On the contrary, the ChatGPT working process involves training to learn about the underlying patterns and structures in input data. Non-supervised pre-training does not rely on a specific task and helps with different use cases, such as dimensionality reduction, clustering, and anomaly detection. On top of it, non-supervised learning can help in training an AI model to understand the semantics and syntax of natural language. As a result, ChatGPT could showcase the ability to create meaningful and coherent text in a conversation.
You can think of non-supervised learning as an important addition to ChatGPT working principle and its ability to gain limitless knowledge. Therefore, developers do not have to worry about the corresponding outputs for certain inputs. On the other hand, developers have to focus on adding more information to the pre-training mechanism of ChatGPT. The pre-training mechanism of ChatGPT is also known as transformer-based language modeling.
What is the Transformer Architecture of ChatGPT?
Another important term after pre-training in the description of ChatGPT is the ‘transformer’ architecture. Transformer architecture refers to a variant of neural networks which help in natural language data processing. Neural networks follow a similar approach for working by utilizing data processing mechanisms across multiple layers of nodes connected to each other.
The answers to “How exactly does ChatGPT work?” would draw your attention toward simple examples of neural networks. For instance, you can assume that a neural network is a football team where every player has been assigned specific roles. Each player works in coordination with other players to move the ball across the ground to score a goal.
You can understand the transformer architecture behind how ChatGPT Works by using the simple example of the team. Transformer architecture works by processing sequences of words through self-attention mechanisms, which would determine the significance of different words in a sequence.
The concept of self-attention in ChatGPT working methodology is similar to the approach in which a reader would look at the previous paragraph or sentence to understand a new word. The transformer model reviews all words in the sequence and helps you understand the context alongside relationship between words.
Enroll now in the AI for Business Course to understand the role and benefits of AI in business and the integration of AI in business.
What are the Components of the Transformer Architecture in ChatGPT?
An explanation for the working of transformer architecture would be incomplete without knowing about the layers in the transformer architecture. You must also note that the layers in the transformer architecture also include multiple sub-layers. First of all, you would find two major sub-layers, such as the self-attention layer and feedforward layer.
The breakdown of ChatGPT working explained from the perspective of transformer architecture also highlights the distinct roles of the sub-layers. Self-attention layer works on determining the significance of words in a sequence. On the other hand, the feedforward layer implements non-linear transformations on input data. As a result, the layers can help in learning and understanding the relationship between different words in a sequence.
Transformers take the input data, such as sentences, and offer predictions according to the input. Gradually, the AI model implements updates according to the extent of correctness in predictions as compared to actual output. The process continues until the transformer learns the context and relationship between words, like a human. As a result, it can offer powerful functionalities for natural language processing tasks, such as text generation and language translation.
The breakdown of ChatGPT working process also reveals the possible ways for using transformer models to create biased or harmful content. Transformer models can learn the biases and patterns in training data for generating harmful, abusive, or fake information. On top of it, the complexities of bias in training transformer models point to the differences among schools of thought. Therefore, it is difficult to create a universal chatbot that could adapt to every perspective and thought process of individuals worldwide.
Which Training Data Has Been Used in ChatGPT?
Another important element in how ChatGPT works is the dataset used for training the AI model. It has been developed on the foundations of GPT-3 architecture. ChatGPT is a generative AI model, implying that it could generate results. It is pre-trained, which suggests that the results generated by ChatGPT are based on pre-training data fed to the model.
Finally, it leverages the transformer architecture for weighing text inputs to develop a better understanding of context. The outline of ChatGPT working methodology must also emphasize the dataset it has used for pre-training. The dataset used for training ChatGPT is WebText2, which is a library featuring more than 45 terabytes of text data.
ChatGPT used the massive dataset for learning relationships and patterns between words as well as different phrases in natural language. Therefore, ChatGPT could generate contextually relevant and coherent responses to user queries. Another crucial detail in the ChatGPT working principle refers to the fine-tuning of its transformer architecture on another dataset. Fine-tuning enables the use of ChatGPT as a chatbot while offering more engaging and personalized experiences for users.
OpenAI has also launched another dataset known as Persona-Chat, which can help in training conversational AI models such as ChatGPT. Persona-Chat dataset features more than 160,000 conversations between human participants, where each participant has a unique persona for describing their interests, personality, and background. Furthermore, OpenAI has also used many other conversational datasets for fine-tuning ChatGPT. The popular entries among training datasets of ChatGPT include DailyDialog, Cornell Movie Dialogs Corpus, and Ubuntu Dialogue Corpus.
The responses to “How exactly does ChatGPT work?” would also include references to the use of unstructured data from the internet in training ChatGPT. Therefore, ChatGPT has also earned knowledge from books, text sources, and websites available online. As a result, it could learn the structures and patterns in language from a general perspective, thereby enabling its applications in sentiment analysis and dialogue management.
Bottom Line
The overview of the working process of ChatGPT reflects the core element of the AI model. It is a Generative Pre-trained Transformer AI model, which can generate results for user queries from the knowledge it gains from pre-training data. The transformer architecture in ChatGPT working methodology helps in recognizing the context and relationship between words in a sentence. On top of it, the massive training datasets used for fine-tuning ChatGPT provide a clear impression of its potential to answer a diverse range of questions. Learn more about ChatGPT fundamentals and how to use it for business use cases and content generation now.
About Author
David Miller is a dedicated content writer and customer relationship specialist at Future Skills Academy. With a passion for technology, he specializes in crafting insightful articles on AI, machine learning, and deep learning. David's expertise lies in creating engaging content that educates and inspires readers, helping them stay updated on the latest trends and advancements in the tech industry.



