

Users have been exploring different types of innovative solutions in the domain of AI. Big players such as OpenAI and Google have established a strong presence in the market. On the other hand, new startups such as Mistral AI also have the capabilities to perform as tough competitors. Mistral AI has been making waves in the AI landscape with its unique model offerings.
Mistral AI introduced some of the most powerful and efficient language models that outperform the popular options. As a matter of fact, the search for insights on Mistral vs. Mixtral differences suggests that Mistral AI has created some of the top-performing language models. However, the play of words in the names ‘Mistral’ and ‘Mixtral’ might lead to confusion. Some of you may believe that they are different language models.
The reality is that Mistral and Mixtral belong to the same family of models with different capacities. The difference between Mistral and Mixtral draws attention to the three open-weight models in the Mistral AI family. The three prominent open-weight models by Mistral AI include Mistral 7B, Mixtral 8x7B, and Mixtral 8x22B. Let us compare these models to find out which one is the best contender.
Enhance your AI skills with our leading Certified AI Professional (CAIP)™ course. Learn the practical applications of AI and boost your innovation.
Overview of Mistral AI Models
Mistral AI offers a broad collection of models tailored for different tasks. You can think of Mistral AI as the shopping mart for language models, where you will find a model for any type of task. The answers to queries like “What is the difference between Mixtral 8x7B and Mistral 7B?” or comparisons between Mixtral 8x7B and Mixtral 8x22B can help you find the recommended model to achieve your goals.
It is important to note that Mistral 7B, Mixtral 8x7B, and Mixtral 8x22B are open-weight models and provide high efficiency. You can access the open-weight models with the help of an Apache 2.0 license that guarantees better accessibility. The models are useful for tasks that require customization and fine-tuning. Some of the most prominent traits of Mistral open-weight models include faster performance, enhanced portability, and control.
Before you find a comparison between the open-weight models by Mistral AI, it is important to understand their fundamentals. Here is an overview of the Mistral AI models that have been phenomenal in the world of AI recently.
-
Mistral 7B
Mistral 7B model is the best example of the efforts by Mistral AI to revolutionize the use of language models. It aims to offer the advantages of better performance in execution with the value of general reductions in size. The Mixtral vs. Mistral debate points largely towards Mistral 7B, the earliest offering of Mistral AI.
Mistral 7B works with around 7 billion parameters and serves the ideal blend between language understanding abilities and computational efficiency. Mistral 7B is ideal for different tasks such as answering questions, generating outlines, or interpreting text. The design of Mistral AI includes different advanced features that can help it work on long-range text.
-
Mistral 8x7B
The Mistral 8x7B is one of the latest offerings in the Mistral AI family of models. It follows an alternative design approach and involves working with a combination of different models to make an effective model. It includes 7 billion parameters that offer the assurance of higher performance and efficiency to empower real-world applications.
The Mistral and Mixtral difference becomes more clearly evident with the efficiency improvements in Mixtral 8x7B that make it useful for real-time applications. As a matter of fact, Mistral 8x7B was successful in outperforming Llama 2, the most effective open-source model with 13 billion parameters.
Learn how to prompt code Llama and how it can provide assistance with diverse programming projects.
-
Mistral 8x22B
The most recent addition to the Mistral AI family of language models is Mixtral 8x22B. It works with a significantly higher number of parameters that help in boosting its capabilities. The open-source model launched in April 2024 has established new standards for efficiency and performance.
Mixtral 8x22B uses the Sparse Mixture of Experts architecture like the Mixtral 8x7B model. It can use only 39 billion active parameters from the 141 billion total parameters. Mixtral 8x22B is the biggest player in the Mistral vs. Mixtral debate as it can offer the assurance of impressive cost efficiency with such a large amount of parameters.
On top of it, Mistral 8x22B has native capabilities for function calling and a constrained output mode. Most important of all, it brings powerful processing capabilities with a context window to accommodate 64k tokens.

How are Mixtral Models Different from Mistral 7B?
The Mistral 7B model, Mixtral 8x7B, and Mixtral 8x22B are all part of the same family. However, the open-weight models have some clear differences between them that prove how Mistral AI family of models offers something new with each iteration.
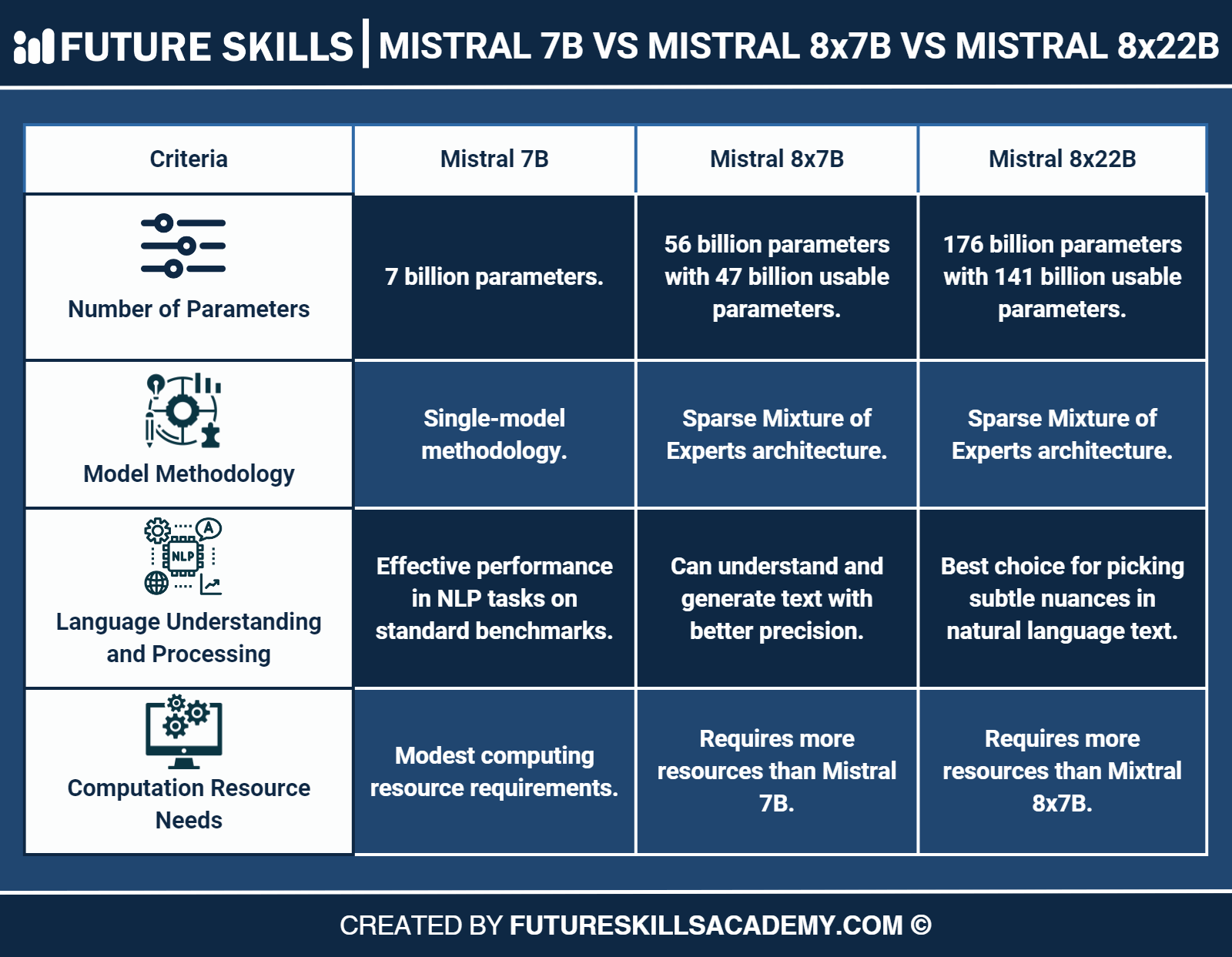
Here are some of the prominent points for comparing Mistral 7B, Mixtral 8x7B, and Mixtral 8x22B models.
-
Number of Parameters
The first thing that you must notice in the difference between Mistral and Mixtral models is the number of parameters. Interestingly, you don’t have rocket science to figure out the number of parameters used in each Mistral AI model. Mistral 7B works with 7 billion boundaries, thereby serving as one of the most lightweight models. On the other hand, Mixtral models are significantly bigger.
For example, the Mixtral 8x7B has around 56 billion parameters, and the Mixtral 8x22B model has around 176 billion parameters on paper. However, the number of parameters that they can use for different tasks is reduced significantly. Mixtral 8x7B can use around 47 billion parameters, while Mixtral 8x22B can use around 141 billion parameters.
-
Model Methodology
The next crucial factor for differentiating Mistral 7B from the Mixtral models is the model methodology. As a matter of fact, the Mistral and Mixtral difference ultimately rounds up on the use of Sparse Mixture of Experts architecture in the Mixtral models. You can think of special architecture as the best way to bring the capabilities of smaller models together to create a larger and more effective framework. On the other hand, Mistral 7B works with a single-model methodology that can limit its capabilities to use the capabilities of multiple models.
-
Language Understanding and Processing
The comparison between Mistral 7B, Mixtral 8x7B, and Mixtral 8x22B also draws attention to the element of language understanding and processing. You can find the answer to “What is the difference between Mixtral 8x7B and Mistral 7B?” in the fact that Mixtral 8x22B outperforms both of them.
The massive parameter size of Mixtral 8x22B helps it understand subtle nuances in natural language. Therefore, it is more likely to provide intelligible and logically relevant responses. You can find better results from Mixtral 8x22B in tasks such as experimental writing, complex question answering, and writing synopsis.
The Mistral 7B is a standout performer, considering its modest size. It has performed effectively on different popular benchmarks for standard NLP tasks. Most importantly, it works best for natural language processing tasks where you need faster responses and computational efficiency.
Therefore, Mistral 7B is more useful for applications that don’t need a lot of parameters. Another player, the Mixtral 8x7B, might not be as strong as Mistral 8x22B. However, it serves some powerful enhancements over Mistral 7B with its unique architecture. It can not only understand but also generate text with better efficiency and precision.
-
Requirement of Computation Resources
Another important aspect that comes to mind when you have to compare Mistral 7B with Mixtral 8x7B and Mixtral 8x22B is the need for computation resources. The Mixtral vs. Mistral debate turns in favor of Mistral 7B as it works with a modest size of parameters. Fewer parameters mean that you can use it with limited computational resources. Therefore, Mistral 7B is an ideal pick for scenarios where you have to work with a limited number of resources.
The Mixtral models have a larger parameter count and would require more computational power for effective operations. In addition, you would need a more extended set of prerequisites for preparation and deployment of the models. At the same time, it is reasonable to believe that Mixtral models would consume more computational resources due to their applications in complex tasks.
Final Words
The comparison between Mistral and Mixtral models shows that you can discover a completely new perspective on language models. Mistral AI has made its presence felt in the AI landscape with its unique collection of open-weight models. As you dive deeper into the Mistral vs. Mixtral debate, you will discover how Mistral 7B is a useful tool for competing against popular language models. In addition, the Mixtral models ensure a new architecture that can expand its capabilities. Learn more about the Mistral family of AI models and how to use them to your advantage right away.
Get an in-depth understanding of how AI works for different industries and harness the full potential of AI with our accredited AI Certification Course.
About Author
James Mitchell is a seasoned technology writer and industry expert with a passion for exploring the latest advancements in artificial intelligence, machine learning, and emerging technologies. With a knack for simplifying complex concepts, James brings a wealth of knowledge and insight to his articles, helping readers stay informed and inspired in the ever-evolving world of tech.



